supervised learning: learn from labeled data. input → output
regression
classification
unsupervised learning: only unlabeled data
cluster
dimensionality reduction
anomaly detection
linear regression
y=wx+b
training set: data used to train the model
cost function:
J(w,b)=2m1i=1∑m(y^(i)−y(i))2
goal: minimize J
it’s a bowl shape surface
gradient descent
how to move downhill
algorithm
w←w−α∂w∂J(w,b)
b←b−α∂b∂J(w,b)
∂w∂J(w,b)=m1i=1∑m(y^(i)−y(i))x(i)
∂b∂J(w,b)=m1i=1∑m(y^(i)−y(i))
where α is the learning rate, which is between 0 and 1. It’s the degree of how large the step downhill we take. if α is too small, gradient descent will be slow. if α is too large, you will get overshoot.
repeat until convergence
batch gradient descent: each step uses all training data
Linear regression with multiple variables
multiple features
use vectors
fw,b(x)=w⋅x+b
vectorization (with numpy)
1
f=np.dot(w,x)+b
compared to loops, it’s a more efficient way
normal equation
only for linear equation to find w,b without iterations
feature scaling
make gradient descent faster
Z-score normalization
x1=σ1x1−μ1
check convergence
if J(w,b) decreases by ⩽ϵ , we declare convergence
feature engineering
design features
polynomial regression
with scikit-learn
Classification
binary classification: true(1) or false(0)
logistic regression
sigmoid function:
g(z)=1+e−z1
logistic regression
fw,b(x)=1+e−(w⋅x+b)1
decision boundary
the line that is neutral (threshold is 0.5) about y=0 or y=1
z=w⋅x+b=0
cost function
if we use the squared error cost which is the same as linear regression, we will get a non-convex curve.
loss function
measures how well we are doing on one training examples
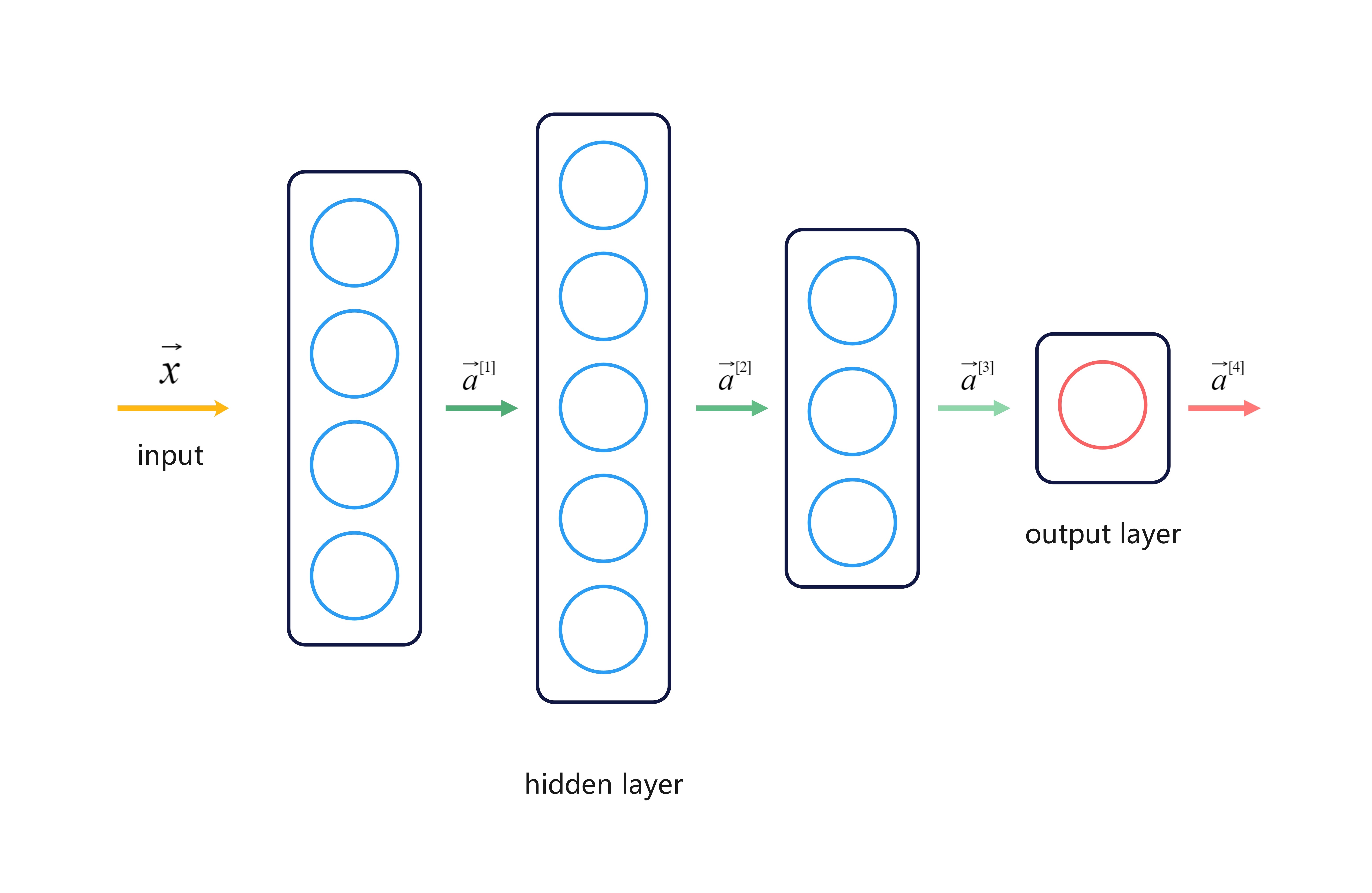
from tensorflow.python.keras.layers import Dense from tensorflow.python.keras import Sequential from tensorflow.python.keras.losses import BinaryCrossentropy
from tensorflow.python.keras.layers import Dense from tensorflow.python.keras import Sequential from tensorflow.python.keras.losses import SparseCategoricalCrossentropy
model=Sequential([ Dense(units=25,activation='relu'), Dense(units=15,activation='relu'), Dense(units=1,activation='linear') ]) #More numercially accurate implementation of softmax model.compile(loss=SparseCategoricalCrossentropy(from_logits=True)) model.fit(X,Y,epochs=100)
Evaluating a model
training set --60%
cross validation set --20%
Jcv(w,b) is used to select a model, pick a set of parameters
test set --20%
Jtest(w,b) is better estimate of how well the model will generalize to new data
The error does not contain regularization term
Jtest(w,b) is better estimate of how well the model will generalize to new data
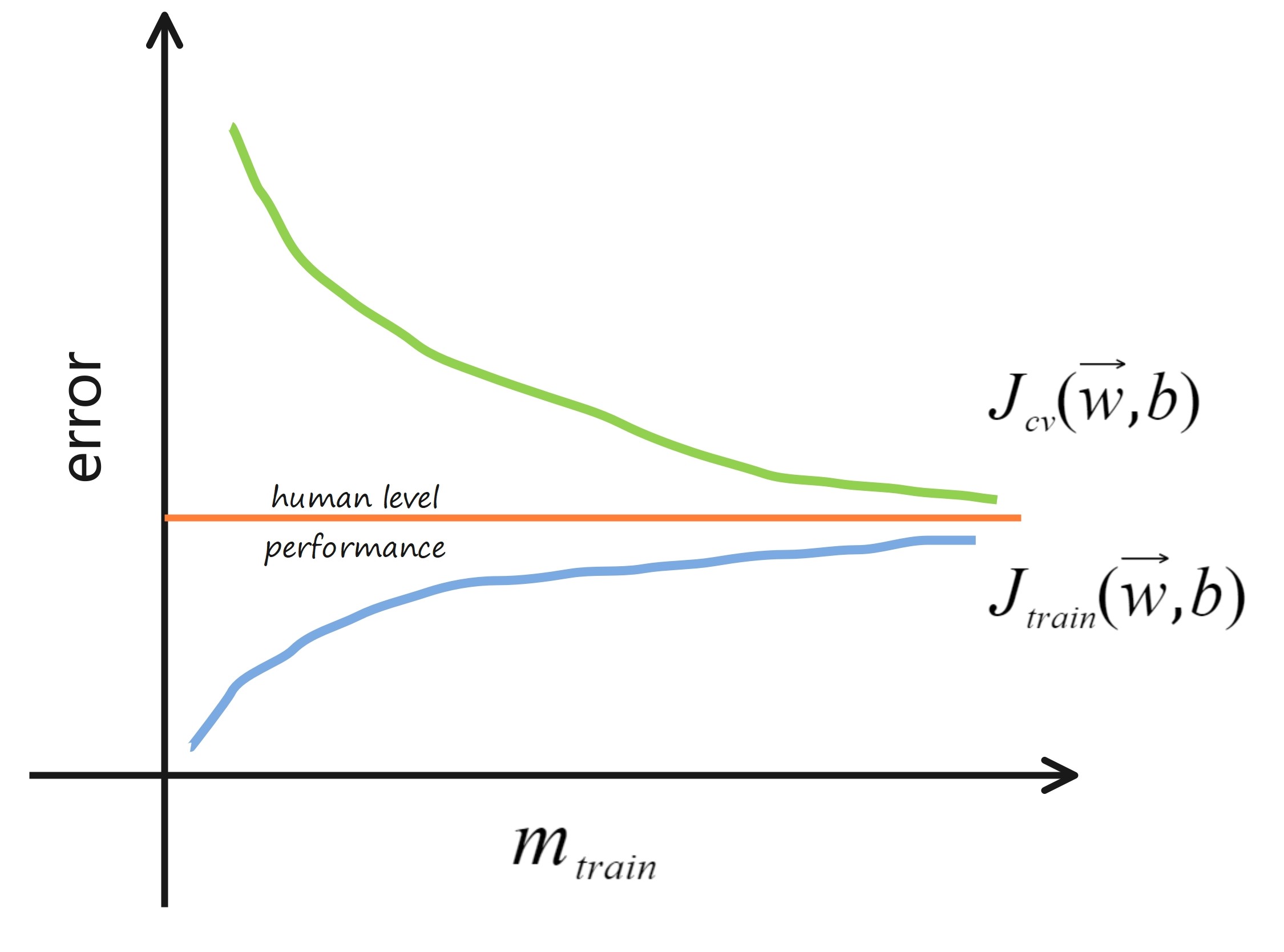
bias & variance
high bias – underfit ←Jtrain(w,b) is high, Jcv(w,b) is high
just right ←Jtrain(w,b) is low, Jcv(w,b) is low
high variance – overfit ←Jtrain(w,b) is low, Jcv(w,b) is high